
 Back
Back


Abstract
This lecture explores various transformer-based approaches that have emerged as powerful alternatives of Convolutional Neural Networks (CNNs) in Computer Vision, and revolutionized the way visual information is analyzed. While CNNs have been the dominant architecture for visual tasks, they face challenges in capturing long-range dependencies and handling variable-sized inputs. Recent research has shown promising results by combining convolutional layers with attention mechanisms. Specifically, attention mechanisms allow the model to focus on relevant regions of the image, enabling better contextual understanding.
Specific transformer architectures designed for computer vision tasks are introduced, including the Vision Transformer (VIT), which replaces the traditional convolutional layers with self-attention mechanisms, facilitating better global information integration. Furthermore, the Detection Transformer (DETR) introduces transformers to object detection, achieving impressive results by utilizing a set-based representation of objects. Similarly, the Segmentation Transformer (SETR) and Segment Anything Model (SAM) leverage transformer architectures for semantic segmentation tasks, demonstrating improved performance in capturing fine-grained details. The lecture also explores unsupervised transformers such as the self-distilling DinO, which leverage self-supervision to learn representations without the need for explicit labels. Finally, the Video Vision Transformer (ViViT) extends the transformer architecture to video understanding, capturing spatiotemporal dependencies and achieving state-of-the-art performance. Several applications are presented, notably in industrial surveillance (pipeline image segmentation and pipeline detection) as well as in natural disaster management (e.g., forest fire detection, detection of flooded houses).
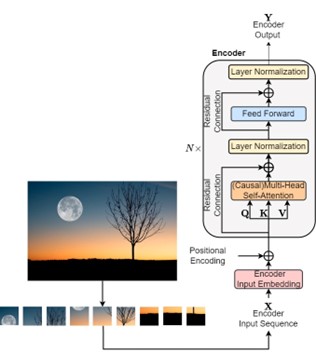
Figure: Typical Vision Transformer architecture.
Lecture by N. M. Militsis and Prof. Ioannis Pitas
Link to the video.

